MPSC Queue 源码分析
在阅读Netty源码中发现在创建EventLoop的时候,内部的taskQueue使用了MpscQueue,MPSC的全称是Multi producer single consumer,单消费者多生产者模型,多生产者会发生竞争要做到无锁使用了CAS,而单一消费者则不需要保证线程安全
而内部大量是用二进制的偶次方特性提高运算效率,并且解决False Sharing问题
创建一个PlatformDependent.<Runnable>newMpscQueue(maxPendingTasks)
private static Queue<Runnable> newTaskQueue0(int maxPendingTasks) {
return maxPendingTasks == Integer.MAX_VALUE ? PlatformDependent.<Runnable>newMpscQueue()
: PlatformDependent.<Runnable>newMpscQueue(maxPendingTasks);
}传入的大小和 MAX_ALLOWED_MPSC_CAPACITY (1 << 30 2的30次方) 取小然后和 2048 取大值,也就是初始的chunk大小为2048最大则为1 << 30,初始的chunk为1024
static <T> Queue<T> newMpscQueue(final int maxCapacity) {
final int capacity = max(min(maxCapacity, MAX_ALLOWED_MPSC_CAPACITY), MIN_MAX_MPSC_CAPACITY);
//MPSC_CHUNK_SIZE 1024
return newChunkedMpscQueue(MPSC_CHUNK_SIZE, capacity);
}
继续调用父类构造器,再次判断初始chuck和capacity不能超过最大2的偶次方(2^31)
public static int roundToPowerOfTwo(final int value) {
if (value > MAX_POW2) {
throw new IllegalArgumentException("There is no larger power of 2 int for value:"+value+" since it exceeds 2^31.");
}
if (value < 0) {
throw new IllegalArgumentException("Given value:"+value+". Expecting value >= 0.");
}
final int nextPow2 = 1 << (32 - Integer.numberOfLeadingZeros(value - 1));
return nextPow2;
}获取下一个偶次方的值,去掉高位0还剩下多少位 取它的偶次方,value – 1 代表如果value恰好是偶次方则返回他本身,如果不是则取下一个距离最近的偶次方
final int nextPow2 = 1 << (32 - Integer.numberOfLeadingZeros(value - 1));numberOfLeadingZeros是integer提供的获取高位0的位运算二分算法,因为int是4个字节32位,第一个if无符号右移16位(刚好是一半,高位补0)如果等于0则高16位没有1,所以n + 16 , 然后左移16位将剩下的16位低位放到高位,下个判断处理1/4部分 以此类推
public static int numberOfLeadingZeros(int i) {
// 如果是0就是32个0
if (i == 0)
return 32;
// 不是0则至少有一个1
int n = 1;
//用2举个例子 00000000 00000000 00000000 00000010 2
if (i >>> 16 == 0) { n += 16; i <<= 16; }
//00000000 00000000 00000000 00000000 i >>> 16
//00000000 00000010 00000000 00000000 i <<= 16
// n = 1 + 16
if (i >>> 24 == 0) { n += 8; i <<= 8; }
//00000000 00000000 00000000 00000000 i >>> 24
//00000010 00000000 00000000 00000000 i <<= 8
// n = 1 + 16 + 8
if (i >>> 28 == 0) { n += 4; i <<= 4; }
//不满足
if (i >>> 30 == 0) { n += 2; i <<= 2; }
//00000000 00000000 00000000 00000000 i >>> 30
//00001000 00000000 00000000 00000000 i <<= 2
// n = 1 + 16 + 8 + 2
n -= i >>> 31;
// 00001000 00000000 00000000 00000000
// 00000000 00000000 00000000 00000000 >>> 31
// n = n - 0
return n;
}最后获取到最近的偶次方两倍的大小给到maxQueueCapacity
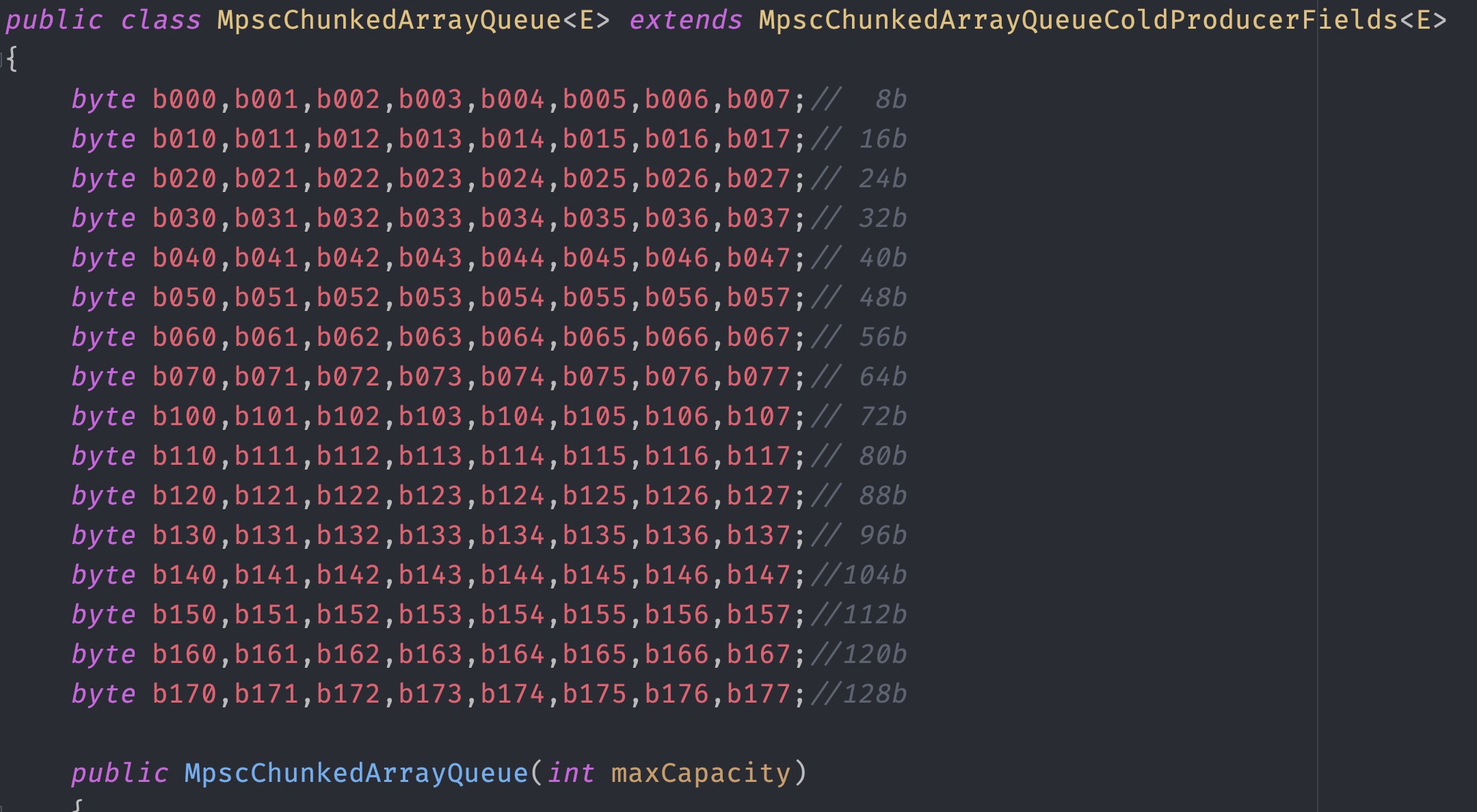
maxQueueCapacity = ((long) Pow2.roundToPowerOfTwo(maxCapacity)) << 1;回过头来看一下MpscChunkedArrayQueue的结构,里面使用了大量的128byte padding,看到的第一眼就知道是用来填充cache line解决False Sharing问题,可问题是为什么使用128 byte而不是64byte?
我们知道市面上绝大部分cpu使用的是64 byte的cache line,下面简单证明一下,macos和linux均使用Intel cpu,可以看到均为64 byte 并且与L1、L2、L3等level无关
getconf LEVEL1_DCACHE_LINESIZE
64
#当然你也可以直接查看device
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
64
# MAC OS
sysctl machdep.cpu.cache.linesize
machdep.cpu.cache.linesize: 64MpscChunkedArrayQueue padding结构如下
128 byte padding ----
8 byte long maxQueueCapacity //最大长度偶次幂
16 byte JUMP = new Object() //填充生产者数组,消费时候使用
16 byte BUFFER_CONSUMED = new Object() //填充消费者数组,消费时使用
4 byte int CONTINUE_TO_P_INDEX_CAS
4 byte int RETRY //重试
4 byte int QUEUE_FULL //队列已满
4 byte int QUEUE_RESIZE //扩容
8 byte long producerLimit //生产上线
8 byte long producerMask // 生产者掩码
8 byte long P_LIMIT_OFFSET //生产者索引位
128 byte padding ----
8 byte long C_INDEX_OFFSET //消费者索引位
8 byte long consumerIndex //消费者下标
8 byte long consumerMask //消费者掩码
128 byte padding ----
8 byte P_INDEX_OFFSET
8 byte producerIndex
128 byte padding ----
突然想起来jdk8+提供了@Contended注解用来自动填充padding,于是我使用JOL查看了如下对象的布局
public class JavaContended{
private long var0;
@Contended
private long var1;
}可以看到@Contended的实现也是基于128 byte对齐的,为啥呢? 其实这只是默认的填充大小可能是为了适配128cache line的cpu 如果恰好是cache line是128 byte而padding是64的话依然会有False Sharing问题,所以牺牲了更大的空间来换取时间
io.netty.example.echo.test.JavaContended object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) N/A
8 4 (object header: class) N/A
12 4 (alignment/padding gap)
16 8 long JavaContended.var0 N/A
24 128 (alignment/padding gap)
152 8 long JavaContended.var1 N/A
160 128 (object alignment gap)
Instance size: 288 bytes
Space losses: 132 bytes internal + 128 bytes external = 260 bytes totalJvm提供的关于Contended一些参数
-XX:-RestrictContended Jdk1.8启用Contended
-XX:ContendedPaddingWidth 调整padding大小
-XX:-EnableContended 开启关闭继续看mpsc queue的源码,初始化最大容量后前还会super调用父类构造器
// 距离初始容量最近的偶次幂
int p2capacity = Pow2.roundToPowerOfTwo(initialCapacity);
// 掩码做位运算用 保证永远是偶数低位为0
long mask = (p2capacity - 1) << 1;
// 实际存储数据的数组 + 1 本质是为了添加jump对象做链表跳转否则越界了
E[] buffer = allocateRefArray(p2capacity + 1);
//生产者buf
producerBuffer = buffer;
producerMask = mask;
//消费者buf
consumerBuffer = buffer;
consumerMask = mask;
//producerLimit = mask本质是控制数组能添加几次元素
//因为pindex每次 + 2 所以当小于等于mask时都会直接添加
//本质就是控制数组添加数量为数组长度-2时进入扩容方法
soProducerLimit(mask);添加元素的方法
@Override
public boolean offer(final E e)
{
if (null == e)
{
throw new NullPointerException();
}
long mask;
E[] buffer;
long pIndex;
while (true)
{
//生产上线值
long producerLimit = lvProducerLimit();
//生产者index 初始是0
pIndex = lvProducerIndex();
//此处仅在处于扩容期间QUEUE_RESIZE cas pindex期间 其他线程进入会等于1
if ((pIndex & 1) == 1)
{
continue;
}
mask = this.producerMask;
buffer = this.producerBuffer;
//消费者index <= 消费上线 触发扩容,否则pIndex+2
if (producerLimit <= pIndex)
{
int result = offerSlowPath(mask, pIndex, producerLimit);
switch (result)
{
case CONTINUE_TO_P_INDEX_CAS://跳出Switch执行casProducerIndex
break;
case RETRY: //重试
continue;
case QUEUE_FULL: //满了入队失败
return false;
case QUEUE_RESIZE: //尝试扩容或入队
resize(mask, buffer, pIndex, e, null);
return true;
}
}
if (casProducerIndex(pIndex, pIndex + 2))
{
break;
}
}
//获取下标对应的数组偏移量
final long offset = modifiedCalcCircularRefElementOffset(pIndex, mask);
//invalid缓存行使其它线程从内存重新读取
soRefElement(buffer, offset, e); // release element e
return true;
}这个方法就是用来判断switch的分支
private int offerSlowPath(long mask, long pIndex, long producerLimit)
{
//生产index 没poll过所以是0
final long cIndex = lvConsumerIndex();
long bufferCapacity = getCurrentBufferCapacity(mask);
if (cIndex + bufferCapacity > pIndex)
{
if (!casProducerLimit(producerLimit, cIndex + bufferCapacity))
{
// retry from top
return RETRY;
}
else
{
// continue to pIndex CAS
return CONTINUE_TO_P_INDEX_CAS;
}
}
// maxQueueCapacity - (pIndex - cIndex) 满了
else if (availableInQueue(pIndex, cIndex) <= 0)
{
// offer should return false;
return QUEUE_FULL;
}
// 否则就把pIndex + 1然后返回resize
else if (casProducerIndex(pIndex, pIndex + 1))
{
// trigger a resize
return QUEUE_RESIZE;
}
else
{
// failed resize attempt, retry from top
return RETRY;
}
}扩容方法,本质是在构建一个链表,总结一下如果初始长度为2那么则是数组套链表每一次都会新建一个链表放到旧数组里,因为pindex + 2 永远和plimit相等直到容量满了返回false,如果长度大于2那么则会填满数组(例如初始长度4(其实+1是5)当添加的元素数量等于长度-2时则会进行扩容,将当前元素放入新数组中并放入旧数组,然后在前面添加一个jump此时数组长度刚好为5)
private void resize(long oldMask, E[] oldBuffer, long pIndex, E e, Supplier<E> s)
{
assert (e != null && s == null) || (e == null || s != null);
//oldBuffer的长度
int newBufferLength = getNextBufferSize(oldBuffer);
final E[] newBuffer;
try
{
//创建一个和原来长度一样的数组
newBuffer = allocateRefArray(newBufferLength);
}
catch (OutOfMemoryError oom)
{
assert lvProducerIndex() == pIndex + 1;
soProducerIndex(pIndex);
throw oom;
}
// 将新数组指向 producerBuffer 也就是每次resize传递进来的都是newBuffer
producerBuffer = newBuffer;
final int newMask = (newBufferLength - 2) << 1;
producerMask = newMask;
//原数组的内存地址偏移量
final long offsetInOld = modifiedCalcCircularRefElementOffset(pIndex, oldMask);
//新数组的内存地址偏移量
final long offsetInNew = modifiedCalcCircularRefElementOffset(pIndex, newMask);
//将元素e添加到新数组中
soRefElement(newBuffer, offsetInNew, e == null ? s.get() : e);// element in new array
//将新数组添加到旧数组的下一个索引位
//比如 offer 1,2
//长这个样子[1,[2](new)](old)
soRefElement(oldBuffer, nextArrayOffset(oldMask), newBuffer);// buffer linked
// ASSERT code
final long cIndex = lvConsumerIndex();
//计算剩余剩余可用大小
final long availableInQueue = availableInQueue(pIndex, cIndex);
RangeUtil.checkPositive(availableInQueue, "availableInQueue");
//赋值给ProducerLimit
soProducerLimit(pIndex + Math.min(newMask, availableInQueue));
//生产者索引 + 2
soProducerIndex(pIndex + 2);
//将旧数组原位置添加jump占位
//长这个样子[1,JUMP,[2](new)](old)
soRefElement(oldBuffer, offsetInOld, JUMP);
}由于是单消费者模式,无并发问题所以poll方法就比较简单了
public E poll()
{
//就是初始的生产者数组
final E[] buffer = consumerBuffer;
//从0开始
final long index = lpConsumerIndex();
//和生产者的初始mask一样
final long mask = consumerMask;
//获取数组初始元素内存偏移量
final long offset = modifiedCalcCircularRefElementOffset(index, mask);
//获取数组index位置的元素
Object e = lvRefElement(buffer, offset);
if (e == null)
{
//可以拿到元素但是没有拿到 可能是因为cache line 还没有share本线程还看不到
//自旋去获取
if (index != lvProducerIndex())
{
do
{
e = lvRefElement(buffer, offset);
}
while (e == null);
}
else
{
//读写索引一致则确实没有元素可以拿了
return null;
}
}
//如果是JUMP则下一个元素必定是一个新数组的引用
if (e == JUMP)
{
final E[] nextBuffer = nextBuffer(buffer, mask);
return newBufferPoll(nextBuffer, index);
}
//将该位置为空(容量不变)
soRefElement(buffer, offset, null); // release element null
//和pindex一样每次 + 2
soConsumerIndex(index + 2); // release cIndex
//返回命中的元素
return (E) e;
}
nextBuffer其实和resize差不多,将当前consumerBuffer改为下一个数组,并且将当前位置使用BUFFER_CONSUMED填充用来标记已经消费过了
private E[] nextBuffer(final E[] buffer, final long mask)
{
final long offset = nextArrayOffset(mask);
final E[] nextBuffer = (E[]) lvRefElement(buffer, offset);
consumerBuffer = nextBuffer;
consumerMask = (length(nextBuffer) - 2) << 1;
soRefElement(buffer, offset, BUFFER_CONSUMED);
return nextBuffer;
}总结
多生产者模型和NioEventLoop需要同时处理多个事件比较契合,而且做到无锁并发提高了性能,通过链表方式扩容减少了array copy,巧妙利用偶次方计算长度,临界值,大量使用内存偏移+unsafe cas极大提高了性能和原子性解决无锁处理并发





